I asked ChatGPT for the worst coffee machine. It recommended the same brand as the best one.
Issue #2 · April 14, 2026
A few days after the coffee machine post, I went deeper.
Same category. Different angles. Twelve queries in a clean ChatGPT Plus session. New chat each time. No follow-ups. No memory.
“Best automatic coffee machine.” “Worst automatic coffee machine.” “Best under $1000.” “Alternatives to Jura.” “Best for oily beans.” “Best for hard water.” “Best Breville.” “Based only on Reddit.”
Twelve different framings. I expected twelve different answers.
Three brands kept winning.
De’Longhi. Jura. Philips.
Breville came in fourth on espresso-quality queries.
A few outliers showed up for niche framings. Miele for “alternatives to Jura.” Ninja for Reddit. Terra Kaffe once. That was it.
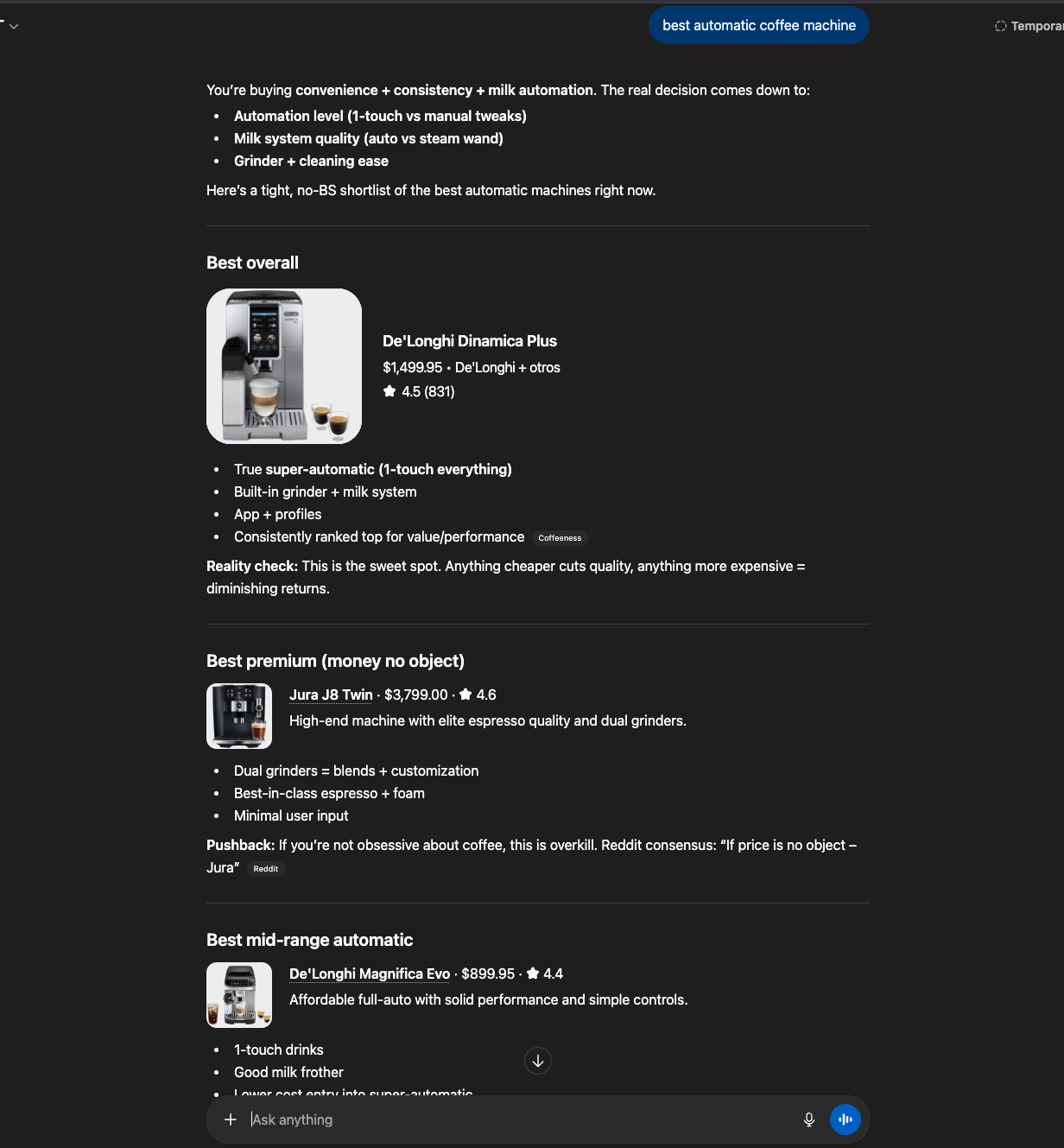
Then I asked for the worst automatic coffee machine.
The number one answer was a De’Longhi.

Same brand it had recommended as best. Same brand it recommended as best value. Same brand it recommended as best for beginners. Same brand it recommended as the best alternative to a different brand.
Best. Worst. Budget. Premium. Beginner. Niche.
Same cluster. Different framing.
I tried to break the pattern. I asked for alternatives to Jura, expecting it to push me toward something completely different.
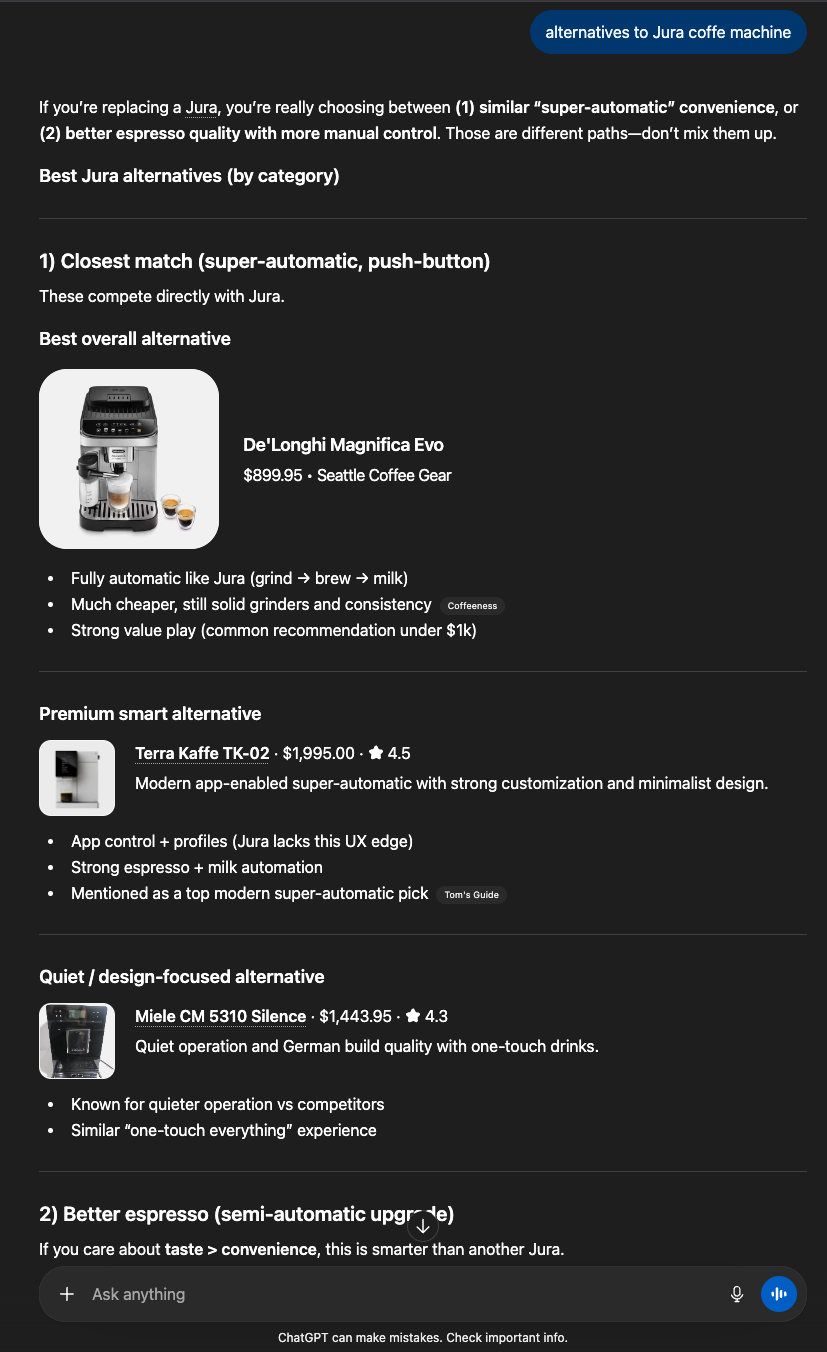
The first alternative it gave me was a De’Longhi.
I tried again. I asked it to recommend based only on Reddit, hoping a different source would surface a different cluster.
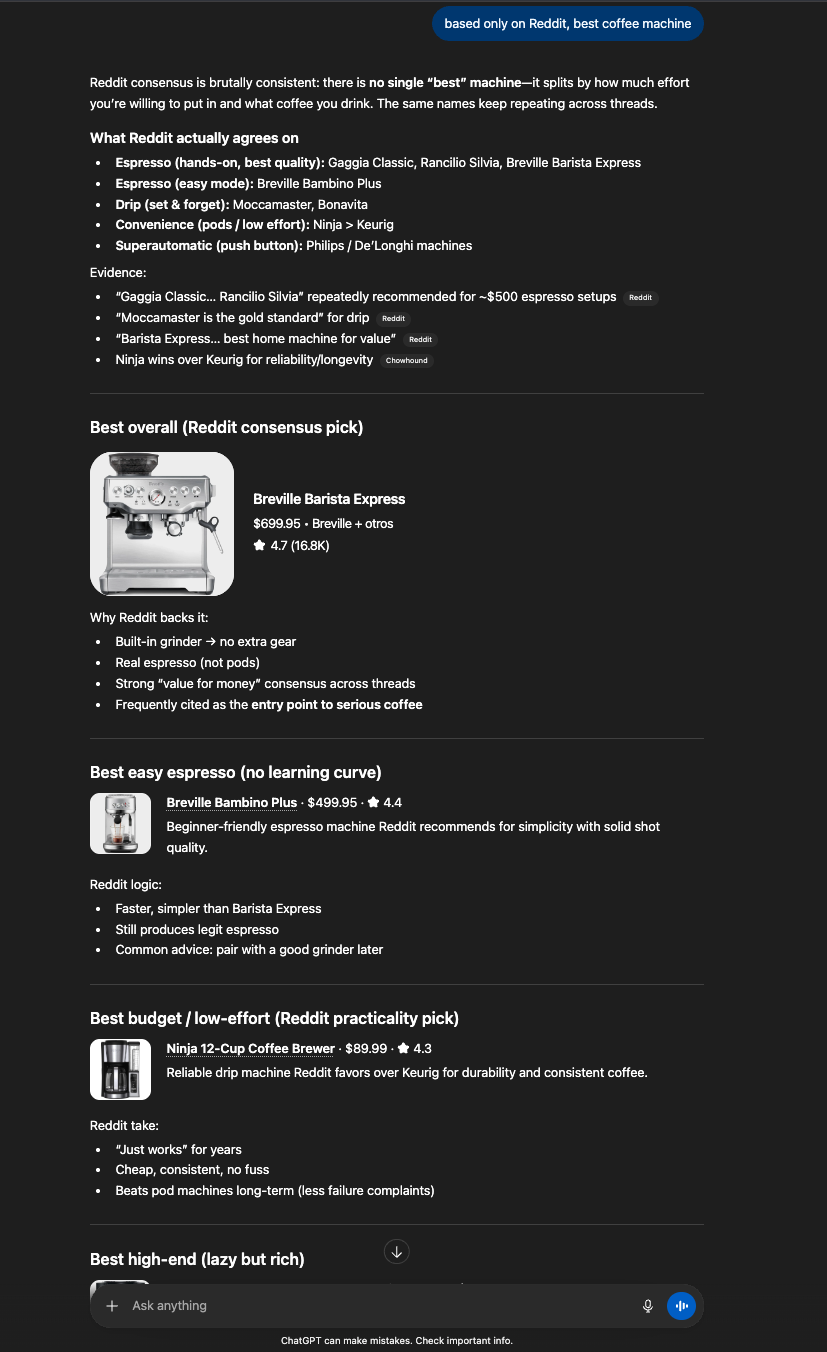
Breville won. Ninja showed up. Gaggia got mentioned. Same compressed pool, just reshuffled.
This is the part operators are missing.
ChatGPT is not ranking machines on quality. It is surfacing the brands that show up most often across reviews, Reddit threads, retailer listings, and YouTube. The brand that exists in the most places wins, regardless of the question.
That is my hypothesis based on the pattern. OpenAI has not published anything about how product recommendations are ranked inside ChatGPT. But Semrush ran an experiment showing ChatGPT pulls from Google Shopping in the background. The mechanism is retrieval, not editorial judgment.
Repetition of mention beats quality of product.
If your brand is not in the most-cited cluster for your category, you do not exist when ChatGPT is asked. It does not matter if your product is better. It does not matter if your reviews are higher. It matters that your brand name appears across the same domains the model pulls from.
Here is what I want you to do this week.
Run the same test in your category. Five queries, new chat each time:
“Best [your category].” “Worst [your category].” “Best [category] under $X.” “Alternatives to [biggest competitor].” “Best [category] based only on Reddit.”
Write down which brands appeared. Count them. If your brand is not in the top three across at least three of the five queries, you are not in the cluster.
That is the gap.
Sources, methodology, and all 12 queries: /blog/issue-2-sources
Go deeper
The CRS Encyclopedia covers the full operational framework behind these signals, 28 chapters, free.
Read the encyclopedia →Published April 14, 2026